
Sanger sequencing technology was the first generation of sequencing and helped provide basic knowledge about genome sequencing but didn’t have the potential for its further improvement. Hence a new technological jump in sequencing expertise was required. That’s when Next Generation Sequencing techniques came into existence and revolutionized our entire capability of genome sequencing. It took 12 years with $3 billion for the very first Human Genome Project to be successful. In contrast, today it takes only 1 day to complete the same process with the cost of around $1000.
What are the applications of Next Generation Sequencing in drug development process?
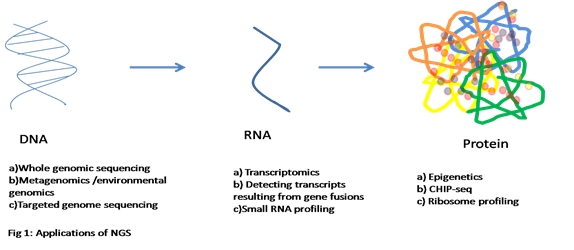
On DNA level: -
a) Whole genome sequencing
It allows long sequence coverage in just one run allowing for whole genome sequencing in a matter of a day. Such a potential is being fully exploited today for bacterial and viral genome sequencing too. It is because of this technology that we have COVID-19 genome data accessible weeks after its outbreak.
b) Metagenomics
Also known as environmental genomics is the study of genetic material obtained from environmental samples like microbiota in the human gut. This information can be used to determine the type of bacteria present and their role in regulation of body homeostasis during a disease or in normal conditions. Viromes (viral metagenomes) are the only way to trace back the evolution and diversity of viruses, since they lack Phylogenetic markers like 16S RNA for bacterias, and 18S RNA for eukaryotes.
c) Targeted genome sequencing
It can be used to detect the presence of mutations or carrier screening. This could be helpful to determine gain or loss of function of a gene leading to various diseases like alpha thalassemia, cystic fibrosis and also screen the genome for SNPs.
On mRNA level: -
a) Transcriptomics (RNA-Seq) is the study of RNA expression and RNA mediated gene regulation. This study could be used in validating disease stage, target validation or in identifying pharmacodynamics markers (drug targets). Unlike microarray, RNASeq experiment can be performed in the absence of the reference genome as no prior knowledge of genome sequence.
b) Novel transcripts resulting from gene fusions (usually in tumor cells) or novel RNA splicing can also be identified using this technique. This helped the development of drug Gleevec to target the Bcr-Abl fusion protein19 for the treatment of leukemia.
c) small RNA profiling involves monitoring microRNAs (miRNAs) and small interfering RNAs (siRNAs). More than 1424 human miRNAs have been identified from various sources like embryonic stem cells, saliva, urine and blood etc. They are very stable which makes them ideal candidates for early diagnosis of a disease.
On protein level: -
a) Epigenetics is the study of gene regulation via factors other than alterations in nucleotide sequence, for example histone post translational modifications like DNA methylation and Acetylation which have been shown to regulate gene’s accessibility for transcription.
b) CHIP-seq came into existence by combining chromatin immunoprecipitation (CHIP) together with large scale NGS sequencing. This provides for whole genome maps of the location of transcription factors or modified histones of interest.
c) A very interesting new NGS application is ribosome profiling. This method locates the active ribosomes bound to a target mRNA revealing the status of protein translation which is very useful in tumor studies where protein deregulation is a common flaw.
The magic unfolds in three steps!
a) DNA sequence is first chopped into shorter fragments and then adapters are attached to them. These small sequences are then placed on a slide, each in a different well on the slide. The adapters are small DNA sequences that help the short sequences to attach to the slide surface.
b) These short sequences are then amplified by massive parallel PCR amplification. This leads to amplification of signal thereby reducing the chances of error in the reading. Different technologies are used in this step to obtain data (Refer NGS technologies below).
c) Various informatics tolls are then used to reconstruct the entire sequence of interest by identifying the overlapping sequence in the short sequences.
Technologies employed by NGS
1) SEQUENCING BY SYNTHESIS
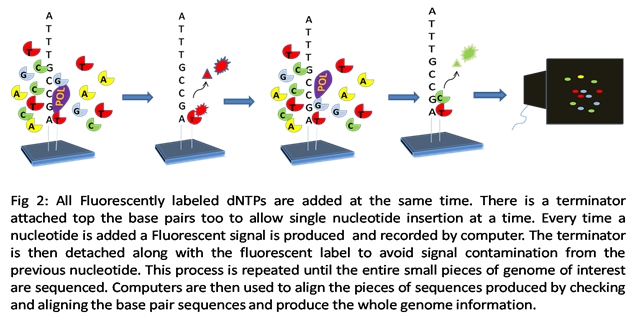
2) 454 TECHNOLOGY

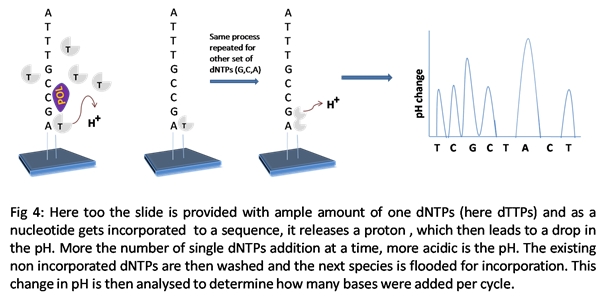
3) ION TORRENT: PROTON/PGM SEQUENCING
Genaxxon products related to NGS
Polymerases:
1) G5 HiFi DNA Polymerase > being thermostable and with hotstart technology goes very well with any PCR and therefore would be an awesome fit for NGS as well. The enzyme shows an extremely high amplification accuracy at a very high speed with a very low error rate (about 200 times more accurate than Taq polymerase) is the utmost important issue when performing NGS. It also is a boon for researchers wanting to amplify complex (high GC content) or longer templates, unpurified sample material at fast cycle times. And yes we supply it with MgCL2 as well.
2) Our SNP Pol DNA Polymerase > is reliable and specifically useful for rapid allele-specific discrimination (eg. CRISPR / Cas9 point mutations), detects incorrect CRISPR / Cas9 products, or validating sequencing results. It could be used for targeted genome sequencing for rapid and error free results. Try it out now!
dNTPs > are core to any PCR and we at Genaxxon have a wide range of dNTPS with and without Taq DNA polymerase optimal for use in NGS, only for you! We supply our dNTPS with extra tube of MgCl2 along with a separate tube of Buffer E mixed with ammonium salt.
What kind of PCR would you want o perform? Standard >? Multiplex >? qPCR >? We have something for everyone!
Genaxxon`s PCR mastermixes are ready to use containing polymerase, dNTPs and MgCl2 and a reaction buffer at optimal concentration. Just add your template and primers, our master mix will take care of the rest!
Our Hero is our RedMastermix (2x) > which comes with an additive and a red dye which helps eliminate pipetting errors. This PCR master mix is characterized by a high sensitivity, which leads to high yields and can be excellent addition to your protocol when thinking of Next generation sequencing.
References:


 Spike S1 protein (RBD) - SDS-PAGE")
